
Why Do We Need New Tooling for Registry Collection?
The Windows registry, an intricate database storing settings for both the operating system and the applications that run on it, is a treasure trove of valuable information. It is known. For this reason, countless offensive security tools have emerged to query the Windows registry, especially for post-exploitation activity. In this space, most tooling falls into two broad categories: specific registry querying with post-processing and arbitrary key querying. One of these tools, PowerUp, is designed to probe for misconfigurations such as unquoted service paths in services and although it brilliantly executes its purpose; PowerUp primarily focuses on fetching a select set of registry keys and relaying the presence of any misconfigurations. This is in contrast to arbitrary querying tools like Cobalt Strike’s reg command, which offers a more generalized utility.
Yet, amidst this vast arsenal, why introduce another tool into the mix?
The reason is straightforward: automated post-processing engines. The uniqueness of our newest registry query tool, developed as a Beacon Object File (BOF), isn’t its ability to collect data but rather its seamless connection to the Nemesis post-processing engine. Instead of two categories of registry querying tools, we now have one and post-processing is performed on every arbitrary registry key queried.
With the release of Nemesis, modern-day security practices emphasize not only the “collection” but also on the “interpretation” of data. It’s no longer enough to merely fetch the data; how the data is structured, processed, and relayed for further analysis holds equal significance. Tools that offer structured and machine-parsable outputs can bridge the gap between raw data collection and actionable insights. As Will aptly highlighted in his blog post titled “On (Structured) Data,” there’s a need for such tooling. This registry query tool, bof_reg_collect, performs a query of a registry path, serializes the data into a binary format, and then sends it back to the C2 as a file. A second tool running on the teamserver captures file downloads with a particular name, deserializes the data, and returns a JSON file that can be used for offensive data analysis.
Harnessing BOFs for Stealthy Data Collection
A quick tangent about Beacon Object Files (BOF): for those unfamiliar, BOFs are common object file format (COFF) libraries that, when tasked by the C2 agent, execute within the agent process and aren’t linked to a C standard library during runtime. The structure of a BOF is very simple. A developer defines a function named go that contains the code to be executed when the BOF is run. The BOF loader built into a compatible C2 agent will find the go function, link the desired functions, and call the go function when tasked. This makes BOFs great for calling a few Win32 API functions and sending the results back to the user. Although BOFs have some downsides such as not having the flexibility of a standard C library, they are still a good option because of their small size. In the Cobalt Strike documentation, there’s an interesting example: “A UAC bypass privilege escalation Reflective DLL implementation may weigh in at 100KB+. The same exploit, built as a BOF, is < 3KB.” (source).
Performing host data collection in any language on Windows typically follows the process of calling one or more Win32 API functions, performing some processing, and then sending that data back to the user in some format like stdout. Because BOFs have a small form factor and relatively operationally secure execution mechanism, they’re a great form factor for writing post-exploitation data collection tooling. To solve the issue of returning structured data for registry collection, the Nemesis team developed a BOF that serializes the data returned from the registry into a standardized format so that it can be converted to JSON for Nemesis to parse.
Step-by-Step Breakdown of bof_reg_collect
To collect registry keys, the registry collection BOF utilizes a series of Win32 APIs, puts that data into a C structure, and serializes the data after all the data has been collected.
Using Win32 API Functions to Query Registries
The process kicks off by querying the registry using the Win32 API functions, specifically utilizing the wide string (-W postfix) versions of those functions. This ensures that registry paths with non-ASCII characters, with the exception of the null character, can be collected. A registry path is first opened with RegOpenKeyExW to get a handle to the registry key. This handle is used as the input for RegQueryInfoKeyW, which returns details about the key like the number of subkeys and values associated with the target path. Next, we iterate on the number of subkeys and call RegEnumKeyExW for each subkey present in the path. If the recursive option is enabled, the tool uses the base path and the new target key name to create a new target key and then performs the registry query function — this time with the new target key. Next, we iterate on the number of values and call RegEnumValueW for each value present in the path. We save the path name, key, value type, and value in a C structure which is pushed to a linked list living on the stack. Finally, we’ll call RegCloseKey to clean up the open handle.
Client-Side Serialization
Now, we have a linked list of C structures that represent the data we want to send back to the C2. Instead of using a text-based serialization format like JSON or YAML, we chose a binary serialization format. The rationale behind this decision is straightforward: with binary serialization, we can achieve a more compact data representation, leading to more efficient storage and potentially faster transmission times. However, we are using a BOF to implement this collector, which presents a unique challenge. Given the nature of BOFs — not being linked to libc — it’s hard to find binary serialization libraries specifically tailored for BOFs. While the ideal would be a BOF-dedicated serialization library (😉), we aren’t entirely at a loss. Cobalt Strike’s Beacon offers the Format API which, with a bit of creativity, can be used to implement a makeshift serializer. The looming question then is: which format should we adopt for this serialization process? I drew inspiration from the popular binary serialization format MessagePack to develop this schema. The proposed serialization format can be represented as a finite state machine, where each node is the type of object consumed and the arrow points to the item to be consumed next. In this diagram, labels with “-sz” refer to the size of the upcoming object. The type is an unsigned integer, so the type size is already known.
This is a MessagePack-esque serialization format where the type of the key comes first and object sizes always precede the object value so object delimiters aren’t required.
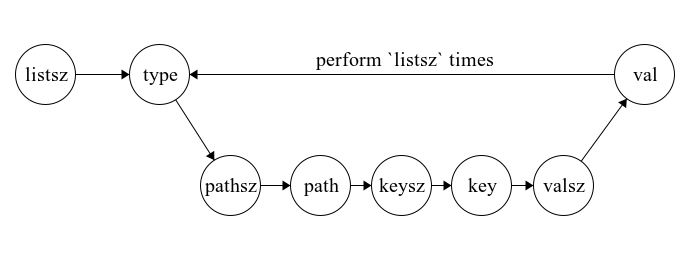
Next, we need to implement this with the Beacon Format API. First, we’ll calculate the size of the required buffer and use BeaconFormatAlloc to allocate a block of memory. Beacon’s Format API lacks a realloc function, meaning our buffer size must be determined in advance. Although it’s possible to reverse engineer the BeaconFormatAlloc functionality for a specific agent to determine how allocation is occurring so that we might use the correct realloc function, we aren’t sure how reallocation may be implemented by other C2 agents (ex. a Mythic agent), so it doesn’t make sense to spend time on this potential workaround. This constraint underscores the significance of bifurcating the collection and serialization processes; knowing the buffer size in advance is non-negotiable. With memory allocated, we can begin writing data. Tools at our disposal include BeaconFormatAppend and BeaconFormatInt. As their names suggest, the former writes character arrays (which is useful for blocks of data like paths, key names, and values) while the latter focuses on integers and is more ideal for writing sizes and type integers. Wrapping up the serialization, BeaconFormatToString amalgamates the formatted data into a singular character array, its length being the one previously determined at the onset of serialization.
The Mythic and Magical CALLBACK_FILE
Once the data is packed into a character array, the next challenge is efficiently exfiltrating it from the target host. Rather than using the more cumbersome CALLBACK_OUTPUT option with BeaconOutput, which returns data to standard out and can be challenging to process, we can use the CALLBACK_FILE type. This option facilitates the exfiltration of our data in a single, easily digestible block which returns the data to the download tab in CobaltStrike. The inspiration for employing this BeaconOutput type and the code utilized for file uploads from a character array was derived from Fortra’s Nanodump implementation. Finally, we’ve gone through all the code that runs on the agent from data collection, representing in an intermediate format, serialization, and exfiltration. Next, we need to process those results on the team server.
The Backend
After the file is downloaded on the team server, we can pass the blob to a custom binary deserializer. The goal for the deserializer will be to take the blob, deserialize the data into a list of Python dictionaries, and then encode the list into a JSON object for Nemesis to consume. Deserialization is a very simple process because we have a well-defined serialization schema. I won’t go into detail about how to deserialize the blob, but the code is on GitHub. We simply perform the inverse of the serialization functionality. Once the data is deserialized into a list of Python NamedTuples, we can call json.dump(..) on the list and get JSON back. Finally, we can call the Nemesis HTTP API to start data ingestion into our offensive analysis pipeline.
How to Use bof_reg_collect From an Operator’s Perspective
To appreciate the straightforwardness of the process, let’s delve into how to use the bof_reg_collect function. A step-by-step example of how easy this function is to use is shown below:
- Import reg_collect.cna from the repository into CobaltStrike.
- Run the bof_reg_collect command with the bof_reg_collect <HKCR|HKCU|HKLM|HKU|HKCC> <path> syntax; for instance, to collect the registry keys associated with the advanced configuration and power interface (ACPI) service, you’d use: bof_reg_collect HKLM SYSTEM\CurrentControlSet\Services\ACPI
- If you’re not using Nemesis, once you’ve acquired the resulting binary data, transforming it into a more digestible JSON format is simple; the repository includes the nemesis_reg_collect_parser.py, which converts the binary blob to JSON. Execute: python3 nemesis_reg_collect_parser.py <input.bin> <output.json> to run the conversion
The Nemesis team has already built a hook for the resulting file into the Nemesis CobaltStrike connector. For every file processed, the Aggressor Script will look for the file “bof_reg_collect.nemesis” which the BOF returns, and send that blob to Nemesis for parsing; Nemesis will run the deserializer automatically, then process the registry entries. As a user, this means all you need to do is execute the bof_reg_collect command and as long as you have the CobaltStrike Nemesis connector, structured data will automatically flow from your team server to Nemesis.
This tool showcases how one might integrate tooling into Nemesis and other potential future offensive security data pipelines. Please take these ideas (and code!) as inspiration and implement your own collection tooling with structured data.
Link to source: GitHub
Shadow Wizard Registry Gang: Structured Registry Querying was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.
The post Shadow Wizard Registry Gang: Structured Registry Querying appeared first on Security Boulevard.
Max Harley
Source: Security Boulevard
Source Link: https://securityboulevard.com/2023/09/shadow-wizard-registry-gang-structured-registry-querying/