How we reverse-engineered the structure of Facebook IDs to improve credit card classification.
(This is blog 3 in our Classification Series. You can also read {children} and {children})
The concept behind data loss prevention (DLP) platforms is simple and powerful: Discover and classify sensitive data then apply policies to prevent that data from leaving the safe perimeter. For example, financial institutions often define policies to prevent credit card information from leaking outside of the organization while inside of unstructured documents (emails, documents, messages, etc).
In the past, volume and complexity of data organizations managed was low enough that simple pattern matching rules were sufficient to implement this guardrail. A single DLP administrator could define a policy that considers every 14-16-digit number a credit card. Even today, Conventional DLP platforms still primarily offer thousands of policies just like this, as their primary means of identifying sensitive data.
Technology and organizational changes in recent years (cloud migration, zero trust, work from home and AI) have accelerated data sharing and created a new reality where the amount of data organizations are managing and being required to protect is growing exponentially. The same policy that once yielded 1-2 alerts per day can yield millions of alerts today. This leads to alert fatigue and the historical “DLP fatigue” that security teams have struggled with for years.
With the rapid evolution of Generative AI in today’s technology ecosystem, one might ask:
"Why not just send the document to an LLM and ask if it contains credit cards?"
The answer to this question is more complex. LLMs are remarkably good at understanding context, and in a one-off scenario, an LLM could likely look at a spreadsheet full of Facebook IDs and tell you "these are ad campaign identifiers, not credit cards." But in practice, this approach simply doesn't work for DLP at scale, and there’s a few reasons why:
- Volume. A large enterprise generates millions of documents and messages per day. Sending each one to an LLM for classification is prohibitively expensive and slow. DLP classification needs to run in real time, on every file, at a fraction of a cent per document. Otherwise user workflows are impacted or, even worse, data exfiltration events are missed entirely.
- Privacy. The foundational purpose of a Data Loss Prevention program is to prevent sensitive data from leaving a controlled perimeter or custody. Sending potentially sensitive documents to an external AI service to check whether they're sensitive is counter-productive to the goals of the security and governance teams in charge of protecting this data.
- Determinism. While an LLM may be able to correctly determine data types in controlled cases, targeted, bespoke techniques solve this problem reliably, cheaper and with more confidence. Algorithmic detections are reproducible, explainable and don't carry the inherent variance of generative models.
LLMs absolutely have a role in MIND's detection pipeline, but as one layer among many. These layers are applied selectively where contextual understanding adds value that algorithms alone can't provide. For high-volume, structural problems. like the one we're about to discuss, a targeted algorithm is faster, cheaper and more reliable.
MIND's approach to detecting sensitive information reflects this philosophy. Instead of relying on any single technique, we built a layered approach that combines pattern matching, statistical algorithms, ML and LLMs. Each of these techniques are applied when and where they’re most effective.
How to perform a Luhn check
If you’ve spent any amount of time in the data security space, you’ve probably heard of the “Luhn Check”. The Luhn algorithm is a checksum formula embedded in credit card numbers that helps merchant vendors (think Point-of-Sale terminals) quickly validate whether a number is a plausible credit card. The last digit of a credit card is the check digit, and we can verify a credit card number by calculating the Luhn checksum over all digits, then comparing the result to the check digit.
For example, here's how a Luhn check works on this machine generated credit card number
4539 1488 0343 6467
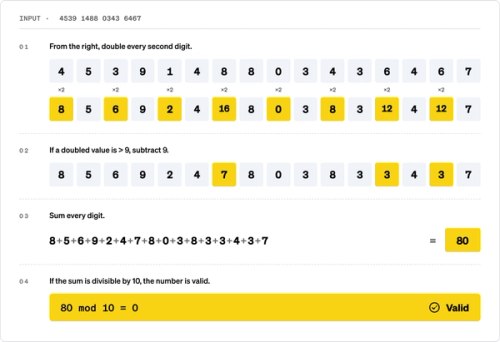
While some DLP vendors utilize Luhn validation to significantly reduce false positives in credit card detection, we were surprised to learn that others do not. The challenge is, even with proper use of a Luhn check, the check digit is a single digit with values 0-9, meaning there is still a ~10% chance that a random 16-digit number will pass the Luhn check by coincidence and produce a false positive.
The challenge compounds even further when combined with other data structures that resemble a credit card number and have a high probability of passing a Luhn check by design, as we’ll discuss below.
Why Facebook IDs are often false positives
Through developing this classification pipeline and onboarding customers over the past year, we began hearing reports from a select few of our customers about false-positives in their credit card and PCI-focused policies. This initiated an unexpectedly thorough investigation from the data science team at MIND.
The start of our investigation was aimed at evaluating ML and context-word approaches to filter out the examples our customers had given. However, this proved unreliable. And even more challenging, the same examples provided by our customers often contained words like "credit," "price" and other financial terminology, making it hard to distinguish at scale by context alone.
After some time, we noticed a common pattern: these customers were running advertising campaigns on Facebook and storing Facebook IDs to track campaign progress. This seemed innocent on the surface.
After much investigation, the commonality between our customers running Facebook advertising and those running into the same suspect false positives was too much for our data science team to ignore.
Initial data gathering
To properly start our investigation, we needed a large sample of Facebook IDs. Luckily, Facebook provides an Ad Library API, which is a public transparency tool that lets anyone query metadata about ads running on the platform. Through this tool, we were able to verify that each and every ad and advertiser page had a unique numeric Facebook ID.
We used this API to find advertisers with large numbers of active ads, then collected all ad IDs from a single large advertiser. This gave us a dataset of IDs from the same origin, similar to what our customers had in their campaign reports. By paginating through the API results, we were able to gather a large dataset of IDs.
Examining these Facebook ID’s visually, it was pretty clear that there is a common digit structure when compared to credit card numbers. Here's an example of what a Facebook ID looks like from that dataset:
5842543952487337
At a glance, it's easy to see why a traditional DLP engine might flag this as a credit card. These Facebook IDs are a 16-digit number that could plausibly pass a Luhn check in good numbers, especially considering the volume of IDs each Facebook campaign was generating.
Once we had enough samples, we started testing hypotheses and running experiments to understand how Facebook IDs are structured.
Reverse engineering the Facebook ID format
To fully test whether or not Facebook IDs could reliably contribute to credit card number false positives, we had to dive into the lower and upper limits of what that ID structure could be.
Understanding the Format
Commonly, IDs serve as a key to uniquely identify and fetch an object from a database. Modern database keys follow common patterns: they have varying levels of randomness built in (for BOLA protection and security purposes), but may also follow structural patterns to allow faster indexing and generation (for example, UUID v7).
Looking at our sample, we could see that Facebook IDs are 10-20 digit numbers, known as a bigint data type, which is a common format for MySQL and SQL-like database keys.
Testing Structural Randomness
If Facebook IDs were randomly generated, we can expect ~10% to pass the Luhn check. With this hypothesis in mind, we decided to run our entire sample set through a Luhn check. Shocked, but not surprised, we found that ~13% of our Facebook ID dataset passed the Luhn check. Even more important was this deviation from the expected 10% is statistically significant and tells us something important: Facebook IDs are not randomly generated. In fact, their predetermined internal structure creates a bias in the digit distribution.
Testing Arithmetic Sequence
Now knowing that these IDs are not generated randomly, we were now focused on determining what predictability existed in the sequence of the IDs.
Looking at the data more carefully, we noticed some patterns:
- The leading digits don't change often.
- Some digit values appear more frequently than others.
- The IDs are numerically close to each other.
These patterns are characteristic of arithmetic sequences, such as:

Which can be made to generate numbers at scale with a pre-defined formula similar to:
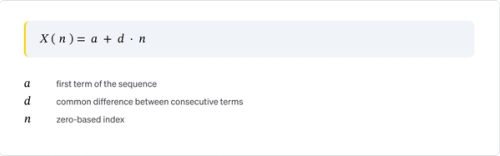
where a is the starting value and d is the common difference.
To test this, we sorted the IDs and computed the differences between consecutive values:
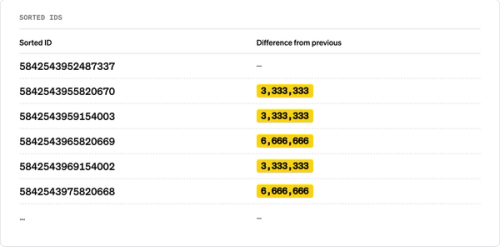
The differences were remarkably consistent: not always identical, but always exact multiples of a common value.
Finding the common difference with GCD
To find the exact step size within the sequence, we computed the Greatest Common Divisor (GCD) of the differences between consecutive sorted IDs. The GCD converged to:

As a data science team, this was our breakthrough. This proved that Facebook IDs aren't random, but instead they follow a pattern with a fixed step of 3,333,333.
Digging further, we found confirmation in Facebook's own code. An archived version of Facebook's JavaScript SDK contains this line for validating 64-bit user IDs:

The number 3,333,333 appears explicitly as an internal constant in Facebook's ID range calculation, confirming that our reverse-engineered value is not a coincidence.
The shard model
The number 3,333,333 immediately suggests a database sharding scheme. In distributed databases, a common pattern formula for generating unique IDs across multiple shards without coordination is:
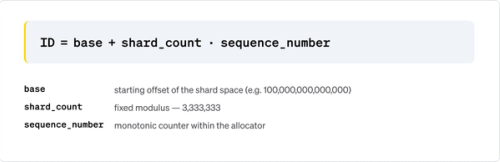
Further, this would reflect:

If we apply this to the same IDs from our earlier example, we see our proof:

Every ID maps to the same shard: 75,124. They all share the same residue because they are all part of the same arithmetic sequence with a step of 3,333,333.
With 3,333,333 shards, each shard is assigned an offset k (where 0 ≤ k < 3,333,333). When a shard needs a new ID, it takes its last ID and adds 3,333,333, stepping over all other shards. This way, every shard generates IDs independently without risk of collision, and all IDs belonging to the same shard share the same residue modulo 3,333,333.
So the Facebook ID format can be described as:
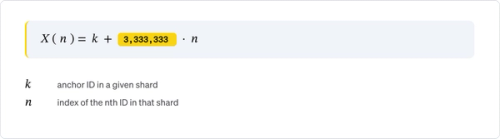
where k is the shard-specific offset, and n is the sequence number within that shard.
This explains:
- Why the IDs form an arithmetic sequence: they are generated within a single shard.
- Why the Luhn pass rate is ~13% instead of ~10%: the structured digit patterns create a non-uniform distribution that biases the checksum.
- Why customer reports cluster: campaign-related entities (ads, audiences, etc.) likely live on the same shard.
A note on the data: This clean result depends on the sample being dominated by IDs from the same shard. In our case, the data came from a single advertising campaign, so the IDs naturally belonged to the same shard. If the sample had contained IDs from many different shards, the GCD of consecutive differences would have been much smaller (potentially 1), and this step would have required additional filtering to isolate per-shard sequences.
Detecting Facebook IDs with a Chi-Square test
Detecting Facebook IDs with a Chi-Square Test
After our investigation and being able to prove the structural consistency of Facebook IDs, we took the opportunity to add another layer to our classification engine. The key insight is:
- Facebook IDs: When you compute ID % 3,333,333, all IDs from the same shard map to the same value (or a small number of values). The distribution across bins is highly non-uniform.
- Real credit card numbers: When you compute number % 3,333,333, the results are distributed roughly uniformly because credit card numbers have no relationship to this modulus.
To do this at scale and efficiently, we use a Chi-Square goodness-of-fit test to distinguish between these two cases. The test compares an observed frequency distribution against an expected distribution (in our case, uniform) and tells us whether the difference is statistically significant.
Here's the detection approach in pseudocode:
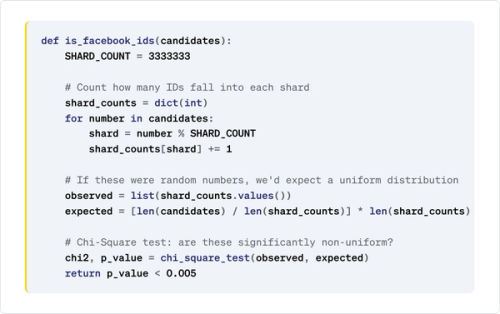
How it works step by step:
- Compute the shard ID for each number: shard = number % 3,333,333.
- Count occurrences per shard: Facebook IDs will cluster into very few shards, while credit card numbers will spread across many.
- Build the expected distribution: if these were random numbers (like credit cards), each observed shard would have roughly the same count (uniform).
- Run the Chi-Square test: if the observed distribution is significantly different from uniform (p-value < 0.005), these are Facebook IDs, not credit cards.
As a single layer, this approach is lightweight and self-contained. It requires no hardcoded ID ranges, no ML model and no context analysis. It's a pure statistical test that exploits the fundamental structure of how Facebook generates IDs. In our classification engine, this sits alongside many other layers (Luhn validation, BIN range checks, context word analysis, ML models, LLM-based classification and more) each catching what the others miss. Even if Facebook's ID space shifts over time, the sharding structure remains, making this particular layer robust and future-proof.
Results
After deploying this detection layer, we eliminated an entire class of false positives for our customers running Facebook advertising campaigns, without any risk of suppressing real credit card alerts. The Chi-Square test cleanly separates the two populations because the underlying data generation processes are fundamentally different: one is structured (sharded database keys), the other is pseudo-random (credit card numbers with a Luhn checksum).
This is just one example of one layer in MIND's classification engine, an approach that goes beyond simple pattern matching. Our pipeline includes dozens of such layers, from statistical tests like this one, through ML models, to LLM-based analysis. Each addresses a different class of false positives or detection gaps. By understanding the structure of the data and having an extensible multi-layer classification engine, rather than relying on any single technique, we can continuously improve accuracy without sacrificing coverage. This means our customers can trust that MIND’s DLP policies will prevent real risk, not negatively impact business.
See MIND for yourself
To see a full demo of the MIND platform, including our advanced multi-layer classification engine, get a {children}.
The post The Facebook ID problem breaking your DLP alerts appeared first on Security Boulevard.
Itai Schwartz
Source: Security Boulevard
Source Link: https://securityboulevard.com/2026/04/the-facebook-id-problem-breaking-your-dlp-alerts/